Building a simple Google Cloud Dataflow pipeline: PubSub to Google Cloud Storage
TL;DR Google provides pre-built Dataflow templates to accelerate deployment of common data integration patterns in Google Cloud. This enables developers can quickly get started building pipelines without having to build pipelines from scratch. This article examines building a streaming pipeline with Dataflow templates to feed downstream systems.
What is Apache Beam?
Apache Beam is a unified programming model for building both batch and streaming data pipelines. Beam decouples the pipeline logic from the underlying execution engine. This enables the pipeline to run across different execution engines like Spark, Flink, Apex, Google Cloud Dataflow and others without having to commit to any one engine. This is a great way to future-proof data pipelines as well as provide portability across different execution engines depending on use case or need. Beam offers great extensibility, enabling developers to build new connectors and transforms to meet their requirements. Best of all it’s open source and boast a active development community, being in a top 3 apache project in 2020 for most commits and top 5 for Github traffic.
What is Google Cloud Dataflow?
Google Cloud Dataflow is a fast, serverless, no-ops platform for running Apache Beam pipelines. Dataflow launches Beam pipelines on fully managed cloud infrastructure and autoscales the required compute based on data processing needs. Google packages over 40 pre-built Beam pipelines that Google Cloud developers can use to tackle some very common integration patterns used in Google Cloud. These provides templates are free to use and publishes the templates on GitHub so developers can use them as starting points when building their own custom Beam jobs.
Building a streaming pipeline with Google Dataflow templates
Scenario (a recent customer request):
- Kubernetes application publishing JSON messages to PubSub
- Write streaming data from PubSub to Google Cloud Storage(GCS) via Dataflow
- The data written to GCS needs to done every 2 minutes AND after the pipeline has processed 1k messages to limit the size of files.
- Signal downstream applications that the file has been written to trigger ingestion
The designed architecture will look similar to this.
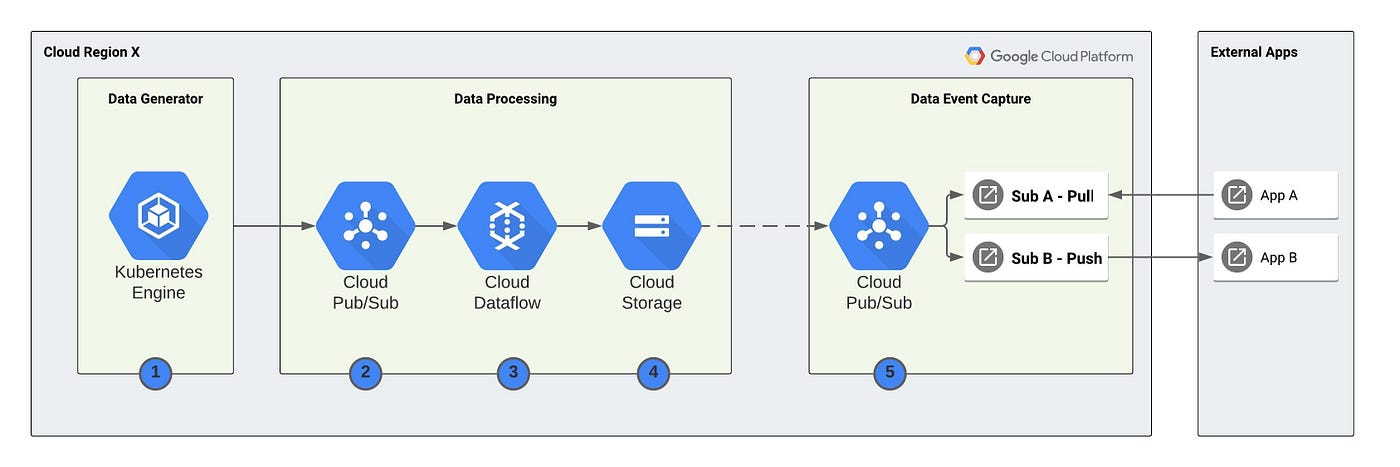
Dataflow Templates
Dataflow templates make this use case pretty straight forward. This scenario will use the Pub/Sub to Text Files on Cloud Storage template BUT it will need to be customized. The default pipeline template flow:
- Read from PubSub topic
- Process the data in 5 minute “fixed” windows
- Append the processing time to the record
- Write the results to GCS
The base template covers 90% of what’s needed with the exception of the windowing and the data processing timestamp append operation. The pipeline will need to be modified in the following areas:
- Trigger the job to write to GCS based on either event count or the 2 minute fixed window elapsing
- The appended processing timestamp will need to be fixed so that it is merged into the source JSON message.
class GroupMessagesByFixedWindows(PTransform):
"""A composite transform that groups Pub/Sub messages based on publish time
and outputs a list of tuples, each containing a message and its publish time.
"""def __init__(self, window_size, num_shards=5, ):
# Set window size to 60 seconds.
self.window_size = int(window_size * 60)
self.num_shards = num_shardsdef expand(self, pcoll):
return (
pcoll
# Bind window info to each element using element timestamp (or publish time).
| "Window into fixed intervals"
>> WindowInto(FixedWindows(self.window_size),
trigger=Repeatedly(AfterAny(AfterCount(1000),
AfterProcessingTime(self.window_size))),
accumulation_mode=AccumulationMode.DISCARDING)
| "Add timestamp to windowed elements" >> ParDo(AddTimestamp())
# Assign a random key to each windowed element based on the number of shards.
| "Add key" >> WithKeys(lambda _: random.randint(0, self.num_shards - 1))
# Group windowed elements by key. All the elements in the same window must fit
# memory for this. If not, you need to use `beam.util.BatchElements`.
| "Group by key" >> GroupByKey()
)
In the code sample above, a trigger has been added to emit the results of a window based on the conditions specified in the scenario. In the code above, we want to emit the contents of a window when it exceeds the 2 minute interval AND when we exceed the 1000 events processed count. This trigger can fire repeatedly in that window range until the window closes. This is good for situations where there may be a large influx of data that would cause the trigger to fire multiple times within the window. The accumulation_mode instructs Beam on how to handle data that has been emitted due to a triggering event. The Discarding option drops data that was emitted while using Accumulating option keeps the data until the window completes.
class WriteToGCS(DoFn):
def __init__(self, output_path):
self.output_path = output_pathdef process(self, key_value, window=DoFn.WindowParam):
"""Write messages in a batch to Google Cloud Storage."""ts_format = "%H:%M"
window_start = window.start.to_utc_datetime().strftime(ts_format)
window_end = window.end.to_utc_datetime().strftime(ts_format)
shard_id, batch = key_value
filename = "-".join([self.output_path, window_start, window_end, str(shard_id)])with io.gcsio.GcsIO().open(filename=filename, mode="w") as f:
for message_body, publish_time in batch:
json_message_body = json.loads(message_body)
json_message_body['publish_ts'] = publish_time
f.write(f"{json_message_body}\n".encode("utf-8"))
In the code above, the message_body is read as a JSON record and has the publish_time added as key-value pair under the publish_ts key.
def run(input_topic, output_path, window_size=1.0, num_shards=5, pipeline_args=None):
# Set `save_main_session` to True so DoFns can access globally imported modules.
pipeline_options = PipelineOptions(
pipeline_args, streaming=True, save_main_session=True, job_name='my-job',
)Lastly, set the job_name pipeline option in the job run definition. This makes identifying the pipeline much easier when searching for it in the Dataflow UI.
Launching the Dataflow job
With the customizations implement, the pipeline can be deployed to the Dataflow service.
export PROJECT_ID=my_project
export REGION=us-central1
export DATA_TOPIC=my_data
export BUCKET=my_bucketpython my-job.py \
--project=$PROJECT_ID \
--region=$REGION \
--input_topic=projects/$PROJECT_ID/topics/$DATA_TOPIC \
--output_path=gs://$BUCKET \
--runner=DataflowRunner \
--window_size=2 \
--num_shards=3 \
--temp_location=gs://$BUCKET/temp
The window_size parameter (in minutes) informs Dataflow the duration of the fixed window. The num_shards parameter instructs Dataflow on how many files to operate on writing data to a destination.
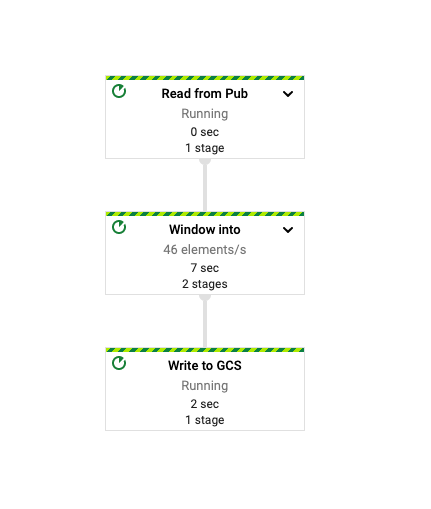
After launching the job, the Dataflow UI will show the newly running job.

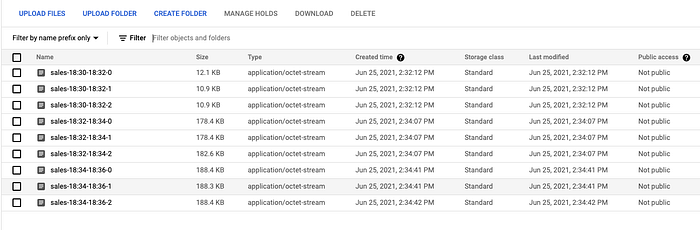
A quick look in the GCS bucket shows that the Dataflow job is writing files from the pipeline. Note that the files appear in groups of 3. That’s because the num_shards parameter was set to 3 and that parameter controls the file IO when writing to the GCS sink.
Capture events from GCS file writes
Capturing events from GCS is really simple. The gsutil notification command below will create a topic that GCS will send bucket events to. Create a subscription to consume the messages so they can be consumed downstream.
export EVENT_TOPIC=my-event-topic
export EVENT_SUBSCRIPTION=my-event-subscription
export BUCKET=my-bucket
export PROJECT_ID=my-project##create notification of storage event for pubsub
gsutil notification create -t $EVENT_TOPIC -f json gs://$BUCKETgcloud pubsub subscriptions create $EVENT_SUBSCRIPTION --topic=$EVENT_TOPIC --topic-project=$PROJECT_ID
Admire the running pipeline!
The pipeline should now be complete! Any downstream application can subscribe to the GCS events being written to PubSub to identify newly arrived data and process them.
(optional) Add custom monitoring and alerting
Google Cloud Monitoring and Alerting is integrated with Dataflow and allows developers to build custom monitoring dashboards and alerting for their running Dataflow jobs. Below is a custom dashboard that tracks the number of messages per minute as well as the latency of a pull request from Dataflow to PubSub. This is a great way to monitor additional metrics that aren’t represented directly in the Dataflow UI.

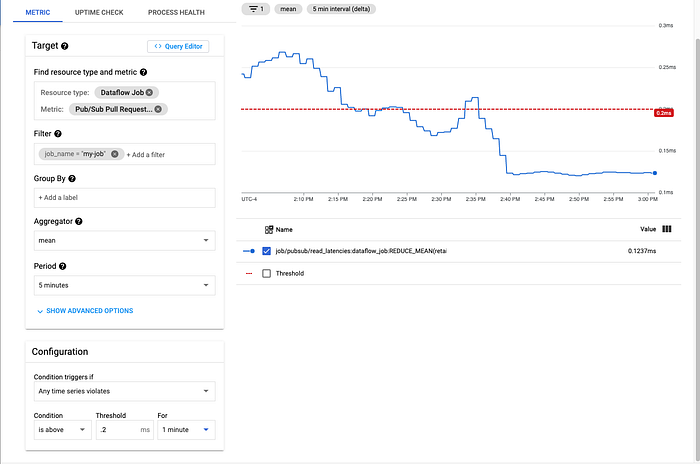
Below is a alert for the job that sends an email or SMS to the SRE team whenever the latency of a PubSub pull request is greater than .2 milliseconds.
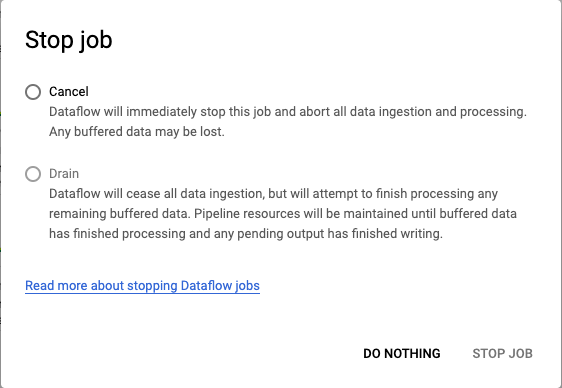
(optional) Modifying the running pipeline
If changes need to be made to the running pipeline the pipeline will first need to be stopped. There are 2 options to stop a pipeline. If modifying code is the goal, the Drain option is ideal because it will stop consuming events from the source and will finalize events buffered in Dataflow. Once the buffer is exhausted, the pipeline will stop and the updates can be applied and the pipeline can be started. Canceling a job is more abrupt and will stop the job immediately with the potential for data loss. Only use this option in situations where its absolutely necessary for a abrupt halt of processing.