Cloud Data Fusion: Using HTTP Plugin to batch API Calls
TL;DR The Data Fusion HTTP plugin enables access to web based data sources and can move the data to a variety of downstream data consumers. Developers can use custom pagination functionality to iterate through a list of API calls to enable large scale batch ingest of data.
Business Challenge
I was recently approached by a customer that had an interesting challenge. They have thousands of curl commands that they use to pull data into a cloud database. The curl commands were from the same endpoint with the exception of having different query parameters. They look something like this:
- https://my-api.com/data?filterA=value1&filterB=value1
- https://my-api.com/data?filterA=value10&filterB=value2
- https://my-api.com/data?filterA=value1&filterB=value3
The customer wanted to move away from storing this logic in script and move the functionality into Google Cloud Data Fusion…and more importantly, they wanted this to be implemented as a single pipeline instead of a pipeline per API call.
Luckily, this can be accomplished by using the HTTP plugin available in Data Fusion Hub. For this blog, we’ll be using the HTTP plugin seen below. The HTTP to HDFS Action plugin will is the same as the HTTP plugin with the exception that it is an action plugin that writes the output of the API operations to HDFS or other filesystem.

The example will use data from Coinstats, a cool website used for managing crypto currency. Coinstats has a great API that can be used for collecting data on current crypto prices, fiat currency rates, exchanges and crypto news. This pipelines built in this article will focus on collecting exchange rates for crypto at major exchanges.
https://api.coinstats.app/public/v1/tickers?exchange=Binance&pair=ETH-USDC
In the example above, the API is pulling the exchange rate for Ethereum to USDC on the Binance exchange. The API call response includes the data for the exchange rate: the currencies involved in exchange (from,to), the crypto exchange doing the conversion, and the conversion rate.
The following sections will explore how to build a pipeline to capture, process and store this data.
Static API Batch Pipeline
If there are a small number of calls that need to be made or the calls are static, meaning they don’t change frequently, the API URL’s can be hard coded in the plugin itself. This makes the pipeline simple and easy to manage, however if any new additions need to be made they will need to be manually added to the pipeline. This section will look at configuring a pipeline for static API calls.

The pipeline for this model is quite simple. There’s a HTTP Plugin to source the data and a BigQuery Plugin for writing the results. Below is the initial configuration for the HTTP Plugin. Take note of the URL listed below. This will come up again when we configure the custom pagination.

The next step is to configure the field mapping. This is where we map the schema for the plugin to the schema of the API response. In our simple example, there are four fields that are returned. We can then map them to the schema that will be output from the plugin (using json path).

In the final section we configure the custom pagination code. This code will enable the plugin to iterate over an array of URLs, calling each URL one at a time. The plugin calls this python definition (get_next_page_url) with every iteration, providing the previous URL, page, and headers used previously as inputs. The code uses those inputs to determine what’s the next URL to call based upon the input URL’s position in the array.
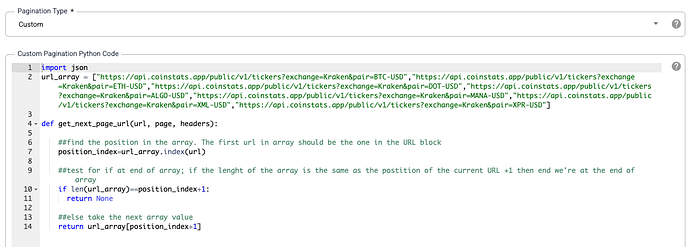
import json
url_array = ["https://api.coinstats.app/public/v1/tickers?exchange=Kraken&pair=BTC-USD","https://api.coinstats.app/public/v1/tickers?exchange=Kraken&pair=ETH-USD","https://api.coinstats.app/public/v1/tickers?exchange=Kraken&pair=DOT-USD","https://api.coinstats.app/public/v1/tickers?exchange=Kraken&pair=ALGO-USD","https://api.coinstats.app/public/v1/tickers?exchange=Kraken&pair=MANA-USD","https://api.coinstats.app/public/v1/tickers?exchange=Kraken&pair=XML-USD","https://api.coinstats.app/public/v1/tickers?exchange=Kraken&pair=XPR-USD"]def get_next_page_url(url, page, headers):
##find the position in the array. The first url in array should be the one in the URL block
position_index=url_array.index(url)
##test for if at end of array; if the lenght of the array is the same as the postition of the current URL +1 then end we're at the end of array
if len(url_array)==position_index+1:
return None
##else take the next array value
return url_array[position_index+1]
What is important here is to recognize that the URL used in the URL field of the plugin is also in the array (as the first value). This serves as a starting point for our array because we will always use its array index +1 to find the next URL to run.
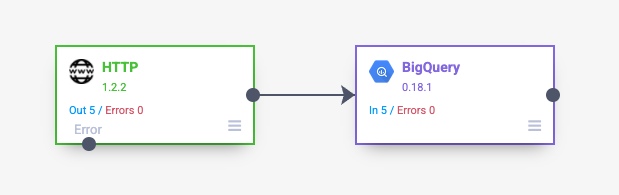

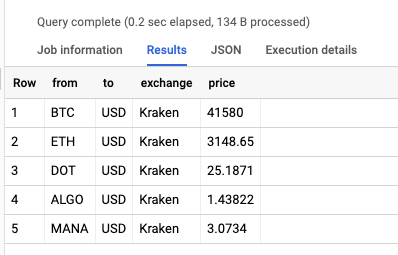
Once the plugin has been configured and linked to a sink plugin it can be executed. Above is the pipeline execution results with 5 calls being made. Below is the result in BQ with 5 records present.
Dynamic API Batch Pipeline
If there are hundreds of URL’s that need to be called or there are frequent changes to the list of URL’s, it makes more sense to use a dynamic approach to sourcing and executing those URL’s. Unlike the single pipeline model in the previous example, this one will require two distinct pipelines. One for sourcing the URL’s and one for executing the calls and storing the result.
Pre-requisites for this approach
- Static single node Dataproc cluster (not ephemeral)
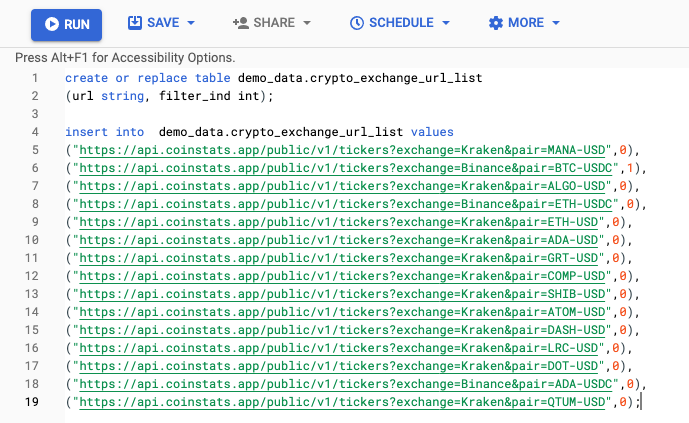
- Database/File to store the list of URL’s
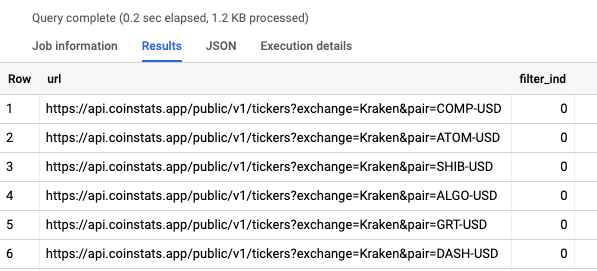
The URL’s that are processed in this example have been stored in BigQuery. The table has 2 fields, URL and filter_ind. The URL field stores the URL to be called while the filter_ind designates what records will be sourced dynamically by the pipeline. If the filter_ind is 0 the records will be sourced by the pipeline, if the filter_ind is 1 it is placed as the starting URL in the plugin itself.
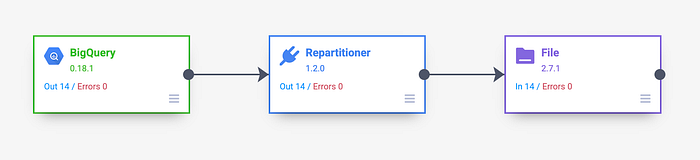
The pipeline to source the URL data is quite simple. Here is the general flow:
- BigQuery Plugin: Pulls the URL data from BigQuery
- Repartitioner Plugin: Ensure that there is only one file output. This is important if there are thousands of calls to make.
- File Plugin: Write the results to the local filesystem of the Dataproc cluster. If we write to HDFS that will generate tons of latency with each API call.
The reason for writing to the local filesystem is for several reasons:
- If the use case requires making potentially hundreds to thousands of calls, it’s more efficient to get that data from the local file system rather HDFS or GCS. Since the plugin calls the python script every iteration that would induce lots of latency into processing data with every read of the file.
- The HTTP plugin doesn’t have any dependency management so using any libraries outside of whats defined seems to encounter issues.
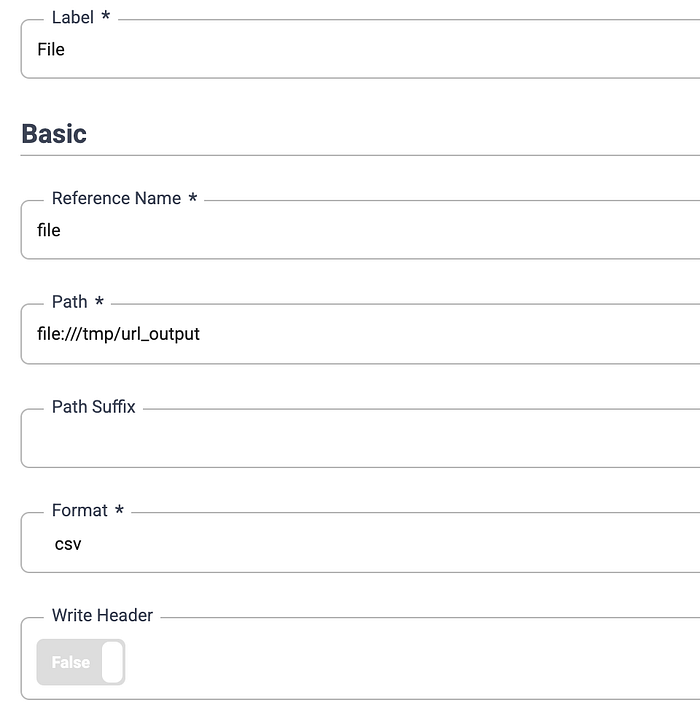
Below is the file configuration plugin. The only changes that need to be made to write to use the file URI scheme (file://). The output from BigQuery will reside in /tmp/url_output. They python pagination script will read from here.
The file that will be written to the file system will look like this: part-r-00000. Since we’re using the repartitioning plugin there should only every be one file.

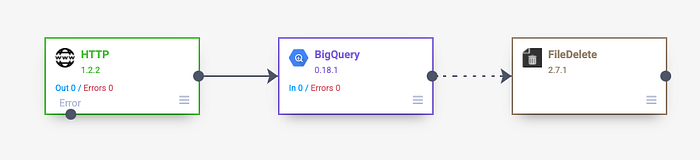
The pipeline for running the API call is fairly similar to what was done in the previous example with the exception of including a FileDelete plugin that cleans up the directory and files created by the upstream pipeline.
The HTTP plugin configuration is the same as the previous example with the exception of some tweaks to the pagination code. Instead of sourcing from an array, the sourcing will be done from the file. Like the code from the previous example, the concept is driven by array matching of the previous URL to find the next array to process. Since the python code is reading reading from a file, there is some formating to eliminate stray whitespace as well as new line characters when reading lines from the file.
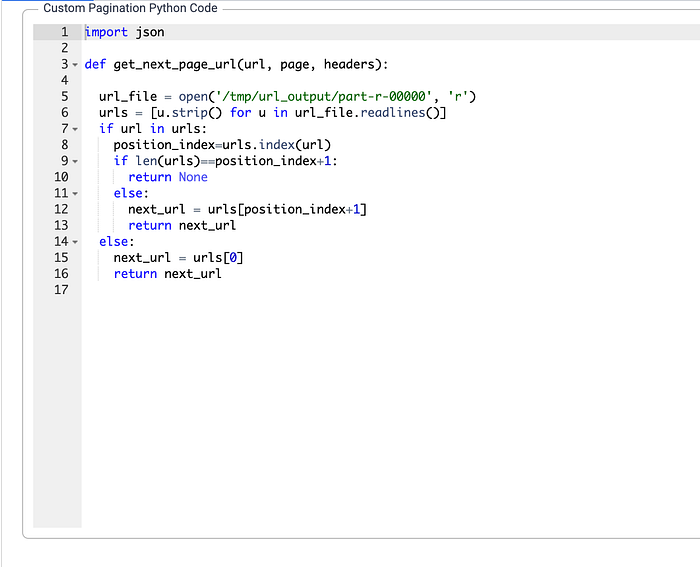
import jsondef get_next_page_url(url, page, headers):url_file = open('/tmp/url_output/part-r-00000', 'r')
urls = [u.strip() for u in url_file.readlines()]
if url in urls:
position_index=urls.index(url)
if len(urls)==position_index+1:
return None
else:
next_url = urls[position_index+1]
return next_url
else:
next_url = urls[0]
return next_url
There are now two pipelines:
- HTTPSourceURLS_final (Sources the URL’s and stores them to a file)
- getHTTPData_filebased_final (takes the file from the previous step and sources the data, and writes to BigQuery)
Since these two pipelines are dependent on each other to run successfully they can be orchestrated via triggers. Triggers basically enable developers to create simple DAG’s of their pipelines. In this example, an inbound trigger is created on the getHTTPData_filebasesed_final based on a successful run of the upstream pipeline.

However, both pipelines must be using the same compute profile. Otherwise, the triggered pipeline won’t be able to locate the URL files generated in the upstream pipeline. In this example, both deployed pipelines share the “cluster-efff” compute profile which is a single node Dataproc cluster.
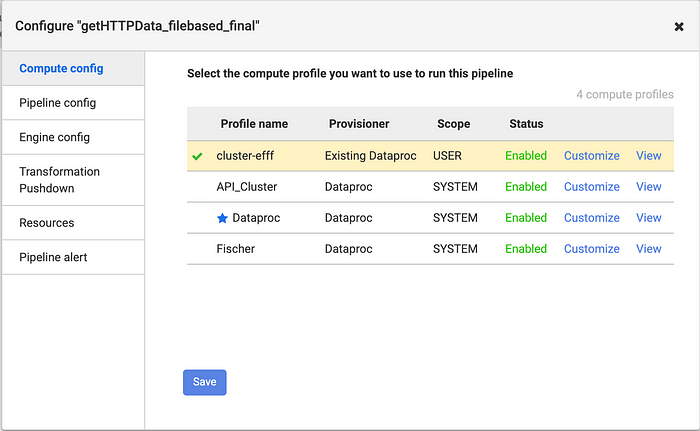
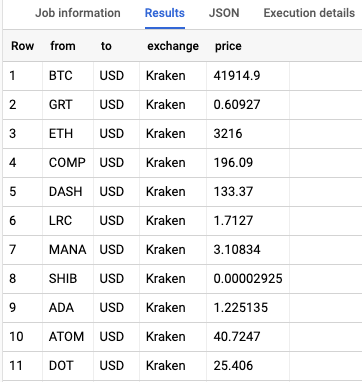
Once these elements are in place the pipelines can be executed. If triggers are used, only the first pipeline needs to be executed and the trigger will handle the rest. If successful the data loaded into BigQuery should look this below. Do note that the price may differ since these are realtime prices.
To find the pipeline templates used in this article: